
- 1 版权声明
- 2 起步
- 3 Git 基础
- 4 Git 分支
- 5 服务器上的 Git
- 5.1 协议
- 5.2 在服务器上搭建 Git
- 5.3 生成 SSH 公钥
- 5.4 配置服务器
- 5.5 Git 守护进程
- 5.6 Smart HTTP
- 5.7 GitWeb
- 5.8 GitLab
- 5.9 第三方托管的选择
- 5.10 总结
- 6 分布式 Git
- 7 GitHub
- 8 Git工具
- 8.1 选择修订版本
- 8.2 交互式暂存
- 8.3 储藏与清理
- 8.4 签署工作
- 8.5 搜索
- 8.6 重写历史
- 8.7 重置揭密
- 8.8 高级合并
- 8.9 Rerere
- 8.10 使用 Git 调试
- 8.11 子模块
- 8.12 打包
- 8.13 替换
- 8.14 凭证存储
- 8.15 总结
- 9 自定义Git
- 9.1 配置 Git
- 9.2 Git 属性
- 9.3 Git 钩子
- 9.4 使用强制策略的一个例子
- 10 Git与其他系统
- 10.1 作为客户端的 Git
- 10.2 迁移到 Git
- 10.3 总结
- 11 Git内部原理
分布式工作流程
- 2018-06-21 09:45:48
- git
- 2088
- 最后编辑:GavinHsueh 于 2018-06-21 09:52:54
你现在拥有了一个远程 Git 版本库,能为所有开发者共享代码提供服务,在一个本地工作流程下,你也已经熟悉了基本 Git 命令。你现在可以学习如何利用 Git 提供的一些分布式工作流程了。
这一章中,你将会学习如何作为贡献者或整合者,在一个分布式协作的环境中使用 Git。 你会学习为一个项目成功地贡献代码,并接触一些最佳实践方式,让你和项目的维护者能轻松地完成这个过程。另外,你也会学到如何管理有很多开发者提交贡献的项目。
分布式工作流程
同传统的集中式版本控制系统(CVCS)不同,Git 的分布式特性使得开发者间的协作变得更加灵活多样。 在集中式系统中,每个开发者就像是连接在集线器上的节点,彼此的工作方式大体相像。 而在 Git 中,每个开发者同时扮演着节点和集线器的角色——也就是说,每个开发者既可以将自己的代码贡献到其他的仓库中,同时也能维护自己的公开仓库,让其他人可以在其基础上工作并贡献代码。 由此,Git 的分布式协作可以为你的项目和团队衍生出种种不同的工作流程,接下来的章节会介绍几种利用了 Git 的这种灵活性的常见应用方式。 我们将讨论每种方式的优点以及可能的缺点;你可以选择使用其中的某一种,或者将它们的特性混合搭配使用。
集中式工作流
集中式系统中通常使用的是单点协作模型——集中式工作流。 一个中心集线器,或者说仓库,可以接受代码,所有人将自己的工作与之同步。 若干个开发者则作为节点——也就是中心仓库的消费者——并且与其进行同步。
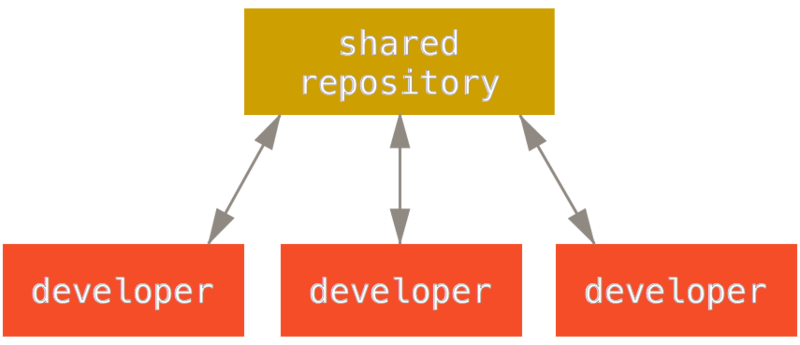
这意味着如果两个开发者从中心仓库克隆代码下来,同时作了一些修改,那么只有第一个开发者可以顺利地把数据推送回共享服务器。 第二个开发者在推送修改之前,必须先将第一个人的工作合并进来,这样才不会覆盖第一个人的修改。 这和 Subversion (或任何 CVCS)中的概念一样,而且这个模式也可以很好地运用到 Git 中。
如果在公司或者团队中,你已经习惯了使用这种集中式工作流程,完全可以继续采用这种简单的模式。 只需要搭建好一个中心仓库,并给开发团队中的每个人推送数据的权限,就可以开展工作了。Git 不会让用户覆盖彼此的修改。 例如 John 和 Jessica 同时开始工作。 John 完成了他的修改并推送到服务器。 接着 Jessica 尝试提交她自己的修改,却遭到服务器拒绝。 她被告知她的修改正通过非快进式(non-fast-forward)的方式推送,只有将数据抓取下来并且合并后方能推送。 这种模式的工作流程的使用非常广泛,因为大多数人对其很熟悉也很习惯。
当然这并不局限于小团队。 利用 Git 的分支模型,通过同时在多个分支上工作的方式,即使是上百人的开发团队也可以很好地在单个项目上协作。
集成管理者工作流
Git 允许多个远程仓库存在,使得这样一种工作流成为可能:每个开发者拥有自己仓库的写权限和其他所有人仓库的读权限。 这种情形下通常会有个代表`‘官方’'项目的权威的仓库。 要为这个项目做贡献,你需要从该项目克隆出一个自己的公开仓库,然后将自己的修改推送上去。 接着你可以请求官方仓库的维护者拉取更新合并到主项目。 维护者可以将你的仓库作为远程仓库添加进来,在本地测试你的变更,将其合并入他们的分支并推送回官方仓库。 这一流程的工作方式如下所示(见 集成管理者工作流。):
项目维护者推送到主仓库。
贡献者克隆此仓库,做出修改。
贡献者将数据推送到自己的公开仓库。
贡献者给维护者发送邮件,请求拉取自己的更新。
维护者在自己本地的仓库中,将贡献者的仓库加为远程仓库并合并修改。
维护者将合并后的修改推送到主仓库。
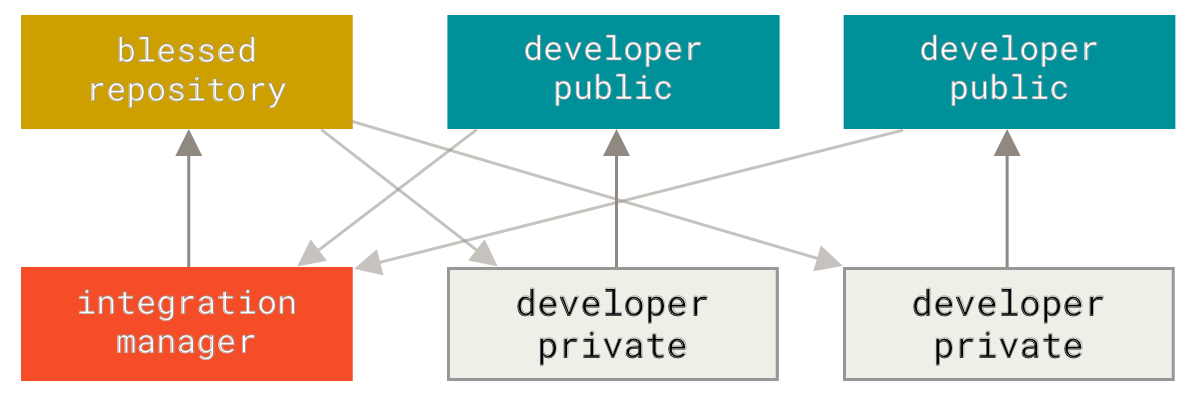
这是 GitHub 和 GitLab 等集线器式(hub-based)工具最常用的工作流程。人们可以容易地将某个项目派生成为自己的公开仓库,向这个仓库推送自己的修改,并为每个人所见。 这么做最主要的优点之一是你可以持续地工作,而主仓库的维护者可以随时拉取你的修改。 贡献者不必等待维护者处理完提交的更新——每一方都可以按照自己节奏工作。
司令官与副官工作流
这其实是多仓库工作流程的变种。 一般拥有数百位协作开发者的超大型项目才会用到这样的工作方式,例如著名的 Linux 内核项目。 被称为副官(lieutenant)的各个集成管理者分别负责集成项目中的特定部分。 所有这些副官头上还有一位称为司令官(dictator)的总集成管理者负责统筹。 司令官维护的仓库作为参考仓库,为所有协作者提供他们需要拉取的项目代码。 整个流程看起来是这样的(见 司令官与副官工作流。):
普通开发者在自己的特性分支上工作,并根据 master 分支进行变基。 这里是司令官的`master`分支。
副官将普通开发者的特性分支合并到自己的 master 分支中。
司令官将所有副官的 master 分支并入自己的 master 分支中。
司令官将集成后的 master 分支推送到参考仓库中,以便所有其他开发者以此为基础进行变基。
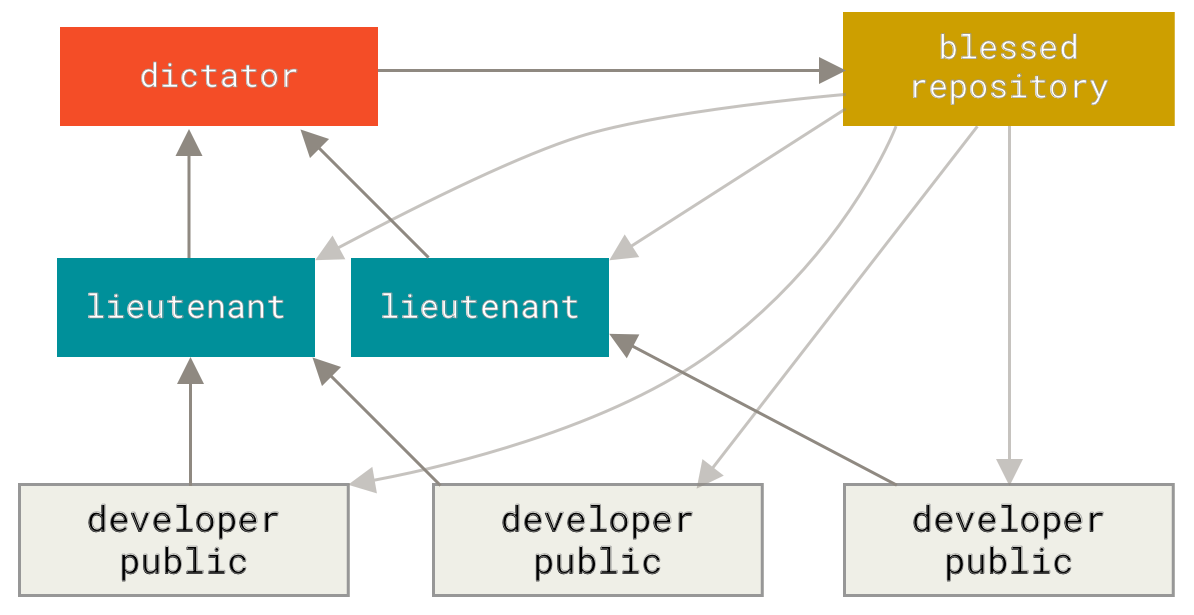
这种工作流程并不常用,只有当项目极为庞杂,或者需要多级别管理时,才会体现出优势。 利用这种方式,项目总负责人(即司令官)可以把大量分散的集成工作委托给不同的小组负责人分别处理,然后在不同时刻将大块的代码子集统筹起来,用于之后的整合。
工作流程总结
上面介绍了在 Git 等分布式系统中经常使用的工作流程,但是在实际的开发中,你会遇到许多可能适合你的特定工作流程的变种。 现在你应该已经清楚哪种工作流程组合可能比较适合你了,我们会给出一些如何扮演不同工作流程中主要角色的更具体的例子。 下一节我们将会学习为项目做贡献的一些常用模式。